東京大学大学院 新領域創成科学研究科 メディカル情報生命専攻 博士課程2年の山谷恭代と申します。私は機能解析イン・シリコ分野研究室に所属しています。
この研究室で私は、ヒトの細胞分化をコントロールするエピジェネティクスという仕組みの働きについて、コンピュータによる解析手法を通じて探ることを研究テーマとして取り組んでいます。
本記事では、研究テーマの2大キーワードでもある「エピジェネティクス」と「コンピュータによる解析手法」について噛み砕いた説明を入れながら、私自身の研究内容について皆さんにお伝えしていきたいと思います。
細胞の分化とエピジェネティクス
「エピジェネティクス 」とは何かを説明する前に、まずはもう少し身近なところから話を始めていきましょう。
私たちヒトは皆、母親のおなかの中で育ち生まれてきます。初めはたった1個の細胞だった受精卵が約9ヶ月をかけてヒトの姿へと成長し、赤ちゃんとして誕生するのです。
ヒトの体ができるまで
母親のおなかの中で受精卵からヒトの形に成長するまでの過程では、どのような変化が起こっているのでしょうか?
ヒトは初め、受精卵というたった1個の細胞の姿をしています。母親のおなかの中で受精卵は分裂を繰り返して細胞数を増やします。
増えた細胞は様々な組織の細胞へと形を変え、ヒトの体のパーツを形作っていきます。神経細胞からなる脳や筋細胞からなる骨格筋がその例です。
このように、細胞が特定の組織細胞へと形態や機能を変化させることを「分化」と呼びます。
細胞の分化には、組織の構成材料であるタンパク質の設計図となる「遺伝子」の働きと、その設計図作りを助けるシステムである「エピジェネティクス」という仕組みが欠かせません。
それでは、「遺伝子」とは何かを具体的に説明しながら、いよいよ「エピジェネティクス」の話に迫っていきます。
遺伝子とは
先ほど、遺伝子とはタンパク質の設計図であると述べました。ここで、わかりやすく一冊の「本」に例えた説明をしていきたいと思います。
細胞の中には、脳や骨格筋などの組織を構成するタンパク質を作るための「設計図」を示す情報がたくさん書き込まれた本があります。
分裂によって増えた細胞1つ1つがもつ本に書かれた内容はどれも全く同じものです。細胞がもつ本に書かれた文章全体がヒトの全遺伝情報を表しています。つまり、個々の細胞がもつ全遺伝情報は共通しているのです。
引き続き「本」の例に当てはめると、本に書かれた文章の中でタンパク質のことを示す文字列部分、すなわち、全遺伝情報のうちタンパク質の情報を示す部分が「遺伝子」となります。
細胞で本の内容の読み取り作業が行われる際に、遺伝子部分が読み取られることを「遺伝子発現」、読み取られた遺伝子(設計図)を元にタンパク質が合成されることを「タンパク質発現」と呼びます。
エピジェネティクスとは
細胞がどの組織の細胞に分化するかによって、発現するタンパク質の種類は異なります。
脳の神経細胞に分化するには神経細胞に必要なタンパク質、骨格筋の筋細胞に分化するには筋細胞に必要なタンパク質が決まっているということです。
さらに、神経細胞や筋細胞が完全に分化するまでには途中いくつかのステップを経由しなければいけません。
このとき、分化を進めるために必要な遺伝子が分化過程の各ステップごとに決まっています。
したがって、ヒトの体を作るためには、分化する組織や分化過程のステップに応じて、多様なタンパク質とそれぞれの設計図となる遺伝子が必要になるのです。
ここで、「遺伝子発現」を「本の内容の読み取り作業」に当てはめる先ほどの例をもう一度考えてみましょう。
分厚い本の各ページの中から、必要な遺伝子情報が書かれた文章箇所を目で追っていって見つけるのは大変です。
このようなとき、文章の重要なところを協調させる「目印」がついていたら便利だと思いませんか?
エピジェネティクスとはまさにこの、文章中の重要部分に目印をつける作業のことを指しているのです。
目印が付けられる重要部分は、遺伝子情報が書かれた箇所や、遺伝子情報が書かれた箇所の前後の文章箇所など様々です。
皆さんの中にもテスト勉強をするときなど、参考書中の重要部分にマーカーペンで線を引いて目立たせる方が多いと思いますが、エピジェネティクスはその作業に近いイメージです。
エピジェネティクスでは、本に書かれた文字列の上からマーカーペンで目印をつけるので、元の文字列自体は書き換えられたりしません。
この、本の文章内容そのものには手を加えずに遺伝子情報を読み取りやすくするということが、エピジェネティクスの大きな特徴となります。
ここまでの説明で、エピジェネティクスの大まかなイメージをつかんでいただくことができたでしょうか?
次節からは、エピジェネティクスが細胞分化の進行にどのように関わっているのか、という話に入っていきます。
なお、これ以降本記事の中で、エピジェネティクスによって遺伝子情報を読み取るために付けられた目印のことを「マーク」と表現することにします。

先行研究例から見える研究背景
遺伝情報中にマークがあることによってある組織細胞への分化に必要な遺伝子の発現量がどのように変化し得るのかという疑問に対して、多くの先行研究例が報告されています。
本記事では、私自身の研究でも扱っている、ヒトの脂肪細胞分化に着目して研究背景を見ていきましょう。
脂肪細胞分化とマークによる分化制御
脂肪細胞とその分化過程
まずは、脂肪細胞がどのような細胞であるのかということと、その分化過程について知られていることを簡単に説明します。
脂肪細胞はヒトの体の中で皮下脂肪組織を構成している細胞です。皮下脂肪組織とは名前の通り体表面の皮の下に、全身にわたって分布する組織です。
日常で意識しやすいのは、おなか周りにつく皮下脂肪組織かもしれません。
ダイエット番組などで話題になりやすい皮下脂肪組織ですが、栄養分の貯蔵、体温の維持、外的刺激からの保護など生命維持に重要な役割を担っています。
皮下脂肪組織を構成する脂肪細胞は、脂肪幹細胞という分化前の細胞がいくつかの段階を介して分化することで最終的に作られます。
脂肪細胞分化促進に働くマークの探索
脂肪細胞分化の進行に対するエピジェネティクスの作用の仕組みについて理解を深めようと試みる研究が、多くの研究者によって行われてきました。
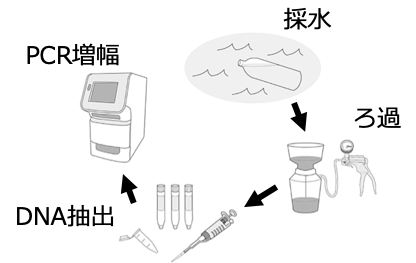
具体的には、エピジェネティクスによって付けられたマークがあることで、脂肪細胞分化に必要な遺伝子群の発現量がどう変化するのかということを、実際に細胞を培養することで調べる方法があります。
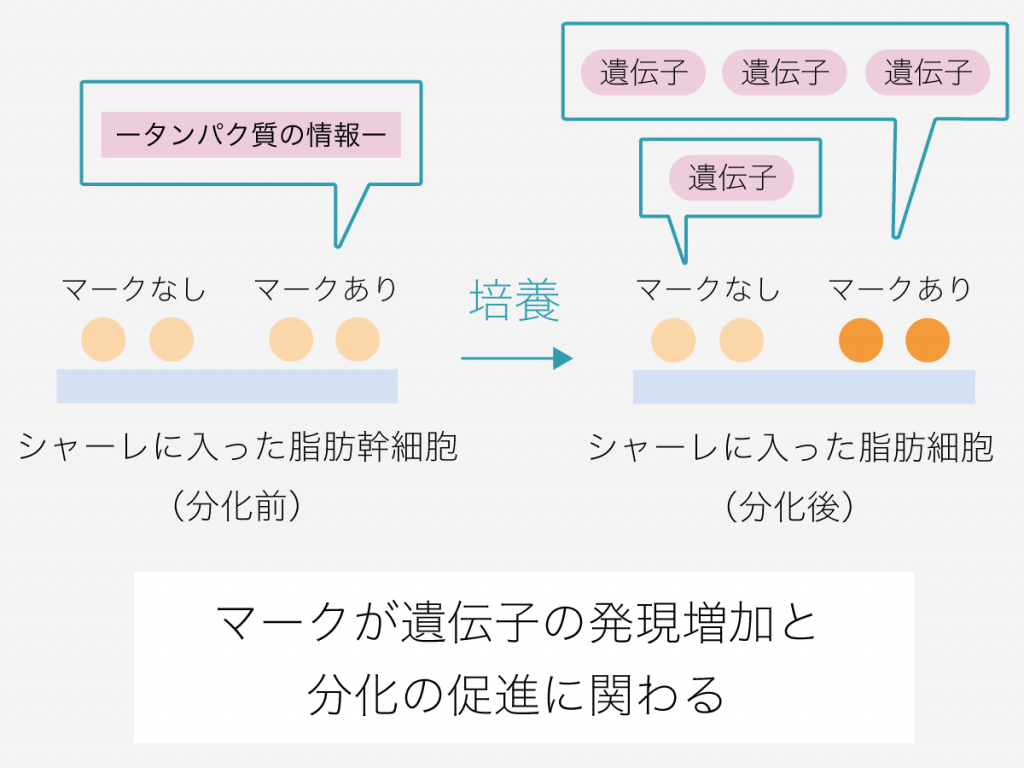
例えば、分化に必要な遺伝子の情報が書かれた部分にマークが付けられている「本」をもつ脂肪幹細胞ともたない脂肪幹細胞を用意し、脂肪細胞分化の進行に違いが出るかどうかを比較して観察したとします。
この実験で、マーク付きの「本」をもつ細胞において分化に必要な遺伝子の発現量が増えると共に脂肪細胞分化の促進が観察されれば、このマークがその遺伝子の発現増加を介して分化を促す働きがあることが導けます。
このように、多くの研究グループが行う地道な細胞培養実験から得られた知見が積み重なることで、分化に必要な遺伝子はどの種類のマークによる作用を受けて発現量を調節されているのかということが明らかになってきました。
細胞培養実験によるアプローチの限界
脂肪細胞分化とエピジェネティクス作用との関わりを調べるために、細胞培養実験によるアプローチが今まで多く行われてきました。
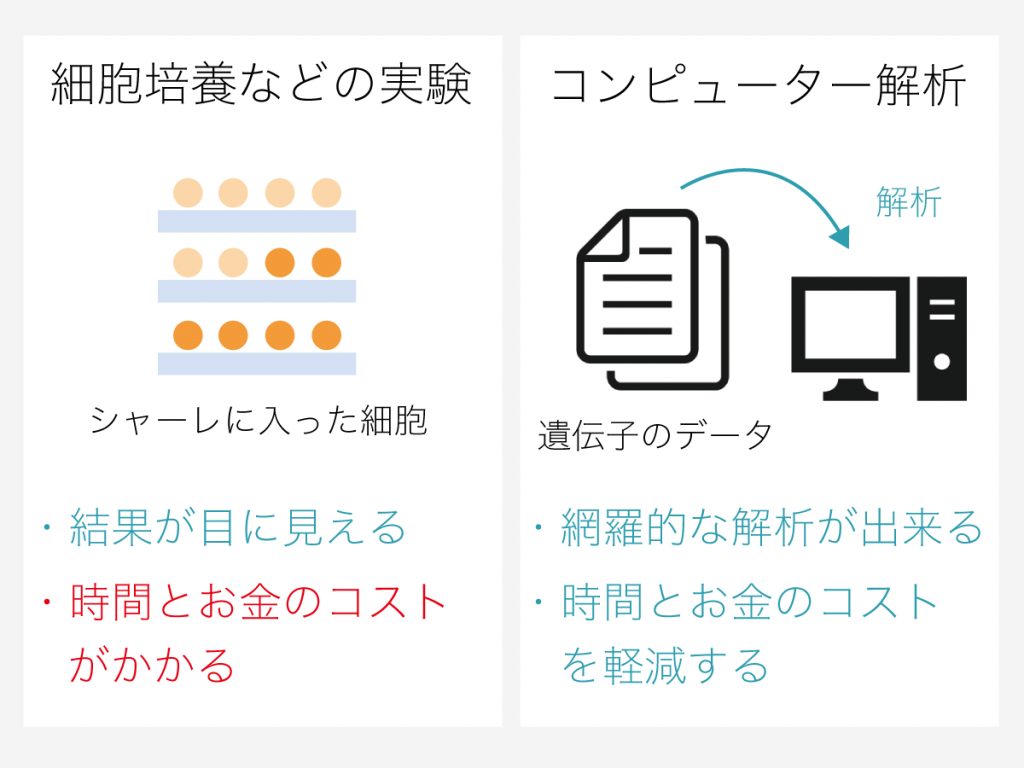
細胞培養実験によるアプローチでは、細胞分化の様子や遺伝子発現の有無を実際に観察して確かめることができるため、結果に説得力をもたせやすいという利点があります。
その一方で、このアプローチには、一回の実験で調べられる研究内容の範囲に限界があるという欠点があります。
脂肪細胞分化に影響を及ぼす可能性があるとされるマークの中には、そのマークが分化に必要な遺伝子の発現量の変化に具体的にどのように関わっているのか、はっきりとわかっていないものもあります。
同じ種類のマークを対象とした異なる研究例で、一方ではそのマークが脂肪細胞分化促進に働くと結論付けているのに対し、もう一方では分化促進に対する働きはもたないと結論付けているといった、互いに矛盾した知見が出ています。
このような研究背景から、脂肪細胞分化のコントロールは、一種類のマークのみではなく複数種類のマーク同士の相互作用によって完全に成り立っているのではないかという仮説が立てられます。
マーカーペンで文字列に目印をつけるイメージに当てはめると、単色ではなく複数の色のマーカーペンを何本か使って目印を付ける感じです。場合によっては、同じ文字列部分に異なる色を重ねて目印を付けることもあります。
同じ文字列に付けられた複数種類のマークが揃って初めて、その文字列部分が示す遺伝子の発現量が、分化するのに十分なレベルまで増加するのではないかというのが具体的な仮説です。
このような仮説を検証するには、様々なマークを対象として分化に必要な遺伝子の発現量の変化に対する影響を網羅的に調べる必要があります。
しかし、細胞培養実験を介して調べる手法では、時間や実験費用面でのコストが高くなってしまい、効率的に研究を進めるのは難しいのです。
コンピュータ解析によるアプローチ
上記のような欠点を補うために近年エピジェネティクスの研究分野でも取り入れられている手法が、私たちも用いているコンピュータ解析によるアプローチです。
このアプローチは、細胞培養といった実験操作は行わず、細胞の遺伝情報データをコンピュータ上で処理することで網羅的な解析を可能にするものです。
先ほど出てきた「本」の例に置き換えると、細胞の遺伝情報データとは、細胞がもつ本の文章を構成する文字列のまとまりを集めてコンピュータ上で見られるようにしたもの、ということになります。
エピジェネティクスの研究分野では、マークが付けられた範囲の文字列のまとまりを集めて見られるようにしたデータが主に用いられます。
このようなデータをコンピュータ処理によって網羅的に解析することで、細胞培養実験を行うよりもはるかに多くのマークを対象とした研究が一度にできるのです。
このアプローチによって、実験操作だけでは見えてこなかったマークの働きに関する知見が蓄積されてきています。
コンピュータ解析で取り組むべき課題
コンピュータ解析のアプローチにより、複数種類のマークが付けられた遺伝情報データを調べられるようになりました。
脂肪細胞分化に重要なマークの存在が断片的に示されてきたものの、複数種類のマークの組み合わせの存在が細胞分化に必要な遺伝子の発現量の変化とどのように関わっているのかということの詳細は未解明であり課題として残っています。
以上の研究背景を踏まえて次章では、私自身の研究テーマとその解析内容について紹介します。
私自身の研究内容
研究のねらい
自身の研究テーマとして私は、脂肪幹細胞から脂肪細胞への分化の過程においてどのようなマークの組み合わせが分化に関わる遺伝子の発現量の変化や分化への影響を及ぼし得るのかを、コンピュータ解析によって調べようと試みました。
解析に用いるデータの取得
私たちが行なっているようなコンピュータ解析で用いるデータは、基本的にWeb上で公開されている遺伝子発現データベース(NCBI Gene Expression Omnibus)のサイトから検索してダウンロードすることで取得できます。
このデータベースには世界中の研究グループからデータ提供が行われていて、私たち含め他の研究者たちは自由にそのデータを元にして、新たな解析に活用することができるのです。
今回私は、ヒトの脂肪細胞分化過程の各段階に沿った細胞を解析に用いることにしました。
データベースから、脂肪幹細胞、分化途中段階の細胞、分化後の脂肪細胞それぞれの遺伝情報データを検索して取得しました。
それぞれの細胞の遺伝情報データには、ある一種類のマークが付けられた範囲の文字列のまとまりが含まれています。
今回の解析では6種類の異なるマークを扱うことにしたため、遺伝情報データはマークの種類数に応じて細胞ごとに6データ分取得します。
解析の流れ
遺伝情報データの解析にはいくつかのステップがあり、各ステップ専用のソフトウェアをコンピュータにインストールして作業を行います。
本記事では、細かい手順やソフトウェアの使い方の詳細に関する説明は割愛し、簡単な流れをつかんでいただく程度にとどめます。
記事の最終章には、参考になる解析手順紹介Webサイトのリンクを載せましたので、より詳しく知りたい方はそちらをご覧になるとデータ解析の雰囲気がわかりやすいかと思います。
大雑把に分けると、データ解析の手順は以下の3ステップから成ります。
ダウンロードした細胞の遺伝情報データそれぞれに対して、各ステップの作業を行います。
解析を行う前にデータの質を整える
データベースからダウンロードした遺伝情報データには、解析の妨げとなる質の悪いデータが混入していることが多いです。
解析を行う前に、そのようなデータを除去してデータ全体の質を整える作業が必要となります。
専用のソフトウェアの設定で質の悪いデータの条件を決め、データの中からその条件に一致する部分を除去します。
遺伝情報の文字列をコンピュータで読み取る
遺伝情報データの質を整えたら次は、遺伝情報の文字列をコンピュータで読み取っていきます。
そして、読み取った文字列をまとまりで捉えながら、細胞がもつ遺伝情報全体から見てどの位置に文字列が合致するのかを調べていきます。
この作業をもう少しわかりやすくすると以下のように例えることができます。
解析用の遺伝情報データは、細胞がもつ「本」の中の文章を文字列のまとまりに区切って断片化したものをランダムに集めたような状態になっています。
この状態では、細胞がもつ「本」の中で何ページ何行目の何文字目から何文字目までの部分に文字列のまとまりがあるのかという位置情報がわかっていません。
そこで位置情報を付加するため、細胞の全遺伝情報を読み込ませておいた専用のソフトウェアを用いて、解析用の遺伝情報データと全遺伝情報を照らし合わせながら、解析用データ中の文字列の位置情報を決めていきます。
マークの集まり具合を定量して数値化する
遺伝情報データに位置情報が付加できたら、エピジェネティクスによって付けられたマークが遺伝情報中のどこの部分にどのくらい集まっているのかを定量していきます。
マークの種類ごとに定量を行い、マークの集まり具合は数値で表します。
各細胞、各種類のマーク、各遺伝子および遺伝子周辺におけるマークの集まり具合の数値化が完了したら、細胞間で数値が高いマークの種類やそのようなマークの組み合わせパターンを調べて比較します。
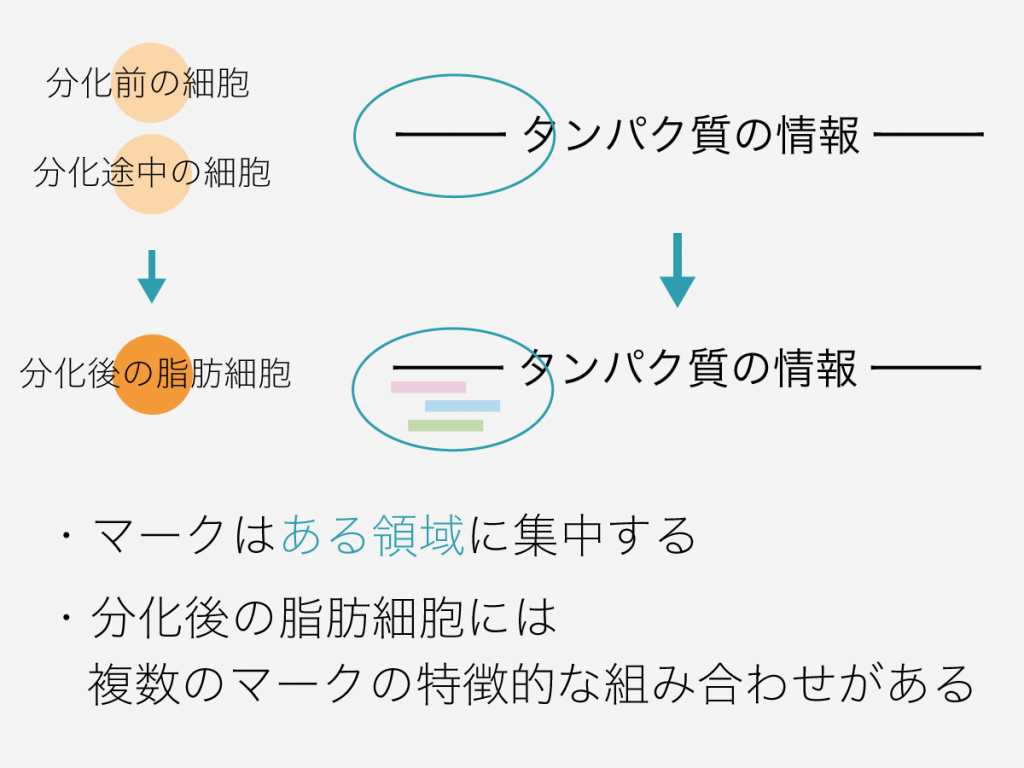
解析結果:分化過程に特異的なマークの発見
上記のステップに沿って、脂肪幹細胞、分化途中の細胞、分化後の脂肪細胞で、遺伝子や遺伝子周辺における6種類のマークの集まり具合を比較したところ、以下のような結果が得られました。
- 各分化過程の細胞において、1種類のマークだけのパターン以外に、2種類以上のマークが組み合わさったパターンが多く見られた。
- 他の分化過程では見られないが分化後の脂肪細胞だけで見られるような、特徴的な組み合わせから成るマークのパターンがいくつか得られた。
- パターンを構成するマークは、遺伝子周辺のうち「遺伝子の発現量の調節に大きく影響することが既に知られている領域」に集まっていた。
これらの結果は、脂肪細胞分化の最終段階から分化後に特徴的な複数種類のマークの組み合わせから成るパターンが細胞の遺伝情報中に存在し、脂肪細胞への最終的な分化の進行に影響する可能性を示すと考えられます。
今後の展開:マークと分化制御との関連性
本記事では私の研究内容の一部分を抜粋して説明しました。
今後、マークの組み合わせパターンの存在が脂肪細胞分化にどのように関わるのかを明らかにするために、さらに解析を進める必要があります。
具体的には、
- 脂肪細胞分化過程における遺伝子の発現量について別のデータ解析から得た結果を重ね合わせ、分化段階ごとに特徴的なマークの組み合わせパターンの存在が遺伝子の発現量変化とどのように関わっているのかを調べる。
- 遺伝子の機能を分類して集めたデータベースの情報を用いて、脂肪細胞分化に働く機能をもつような遺伝子を探す。
などが、これから取り組んでいきたい解析項目です。
終わりに
最後に、私たちの研究室紹介と進路選択に向けたささやかなアドバイスをお伝えします。
研究室紹介
私たちの研究室では、コンピュータによる解析手法を使って、メンバーそれぞれが生命科学に関する独自の研究テーマに日々取り組んでいます。
生命科学分野の研究に関心がある・コンピュータ解析を使った研究に取り組んでみたい・国際色豊かな研究室ライフを送ってみたいという方はぜひ、私たちの研究室を一度のぞいてみませんか?
興味がある方は、よろしければ下記の研究室Webサイトや紹介ポスターをご覧になってみてください。
大学院から新しい分野へ踏み込む
研究室メンバーの専攻がある東京大学大学院 新領域創成科学研究科では、主に大学院生(修士・博士)からの受け入れを行っています。
そのため、他大学からこちらに大学院入学する学生や、留学生も大勢います。
私自身も他大学の出身で、今の研究室には修士課程から入学しました。
学部生の頃は生物学を専攻していたため、コンピュータによる解析手法は大学院入学後、初歩的なところから学び始めました。
コンピュータ解析の知識・経験ゼロからスタートしたという学生は、研究室内で私の他にも何人かいます。
こちらの大学院では、元々他分野を専攻していた学生向けに、学内主催の講習会や大学院の講義でコンピュータ解析の基本を学ぶチャンスが多くあります。
私たちの研究室でもメンバー同士で解析手法についてアドバイスを積極的に交わしているので、自身の習得度に合わせてステップアップしていけます。
進路選択へのアドバイス
研究テーマ選びや進学先選択について、誰にとっても大なり小なり迷いはつきものであると思います。
なかなかやりたい方向が決まらなかったり、決まっていたのだけれど時間がたつうちに考えが揺らいできたりなど、人それぞれ悩み方も違うでしょう。
私自身は学部入学の頃から大学院進学しようという意思があったものの、いざ進路決定する時期が近づいたとき、研究テーマの方向性に迷いが生じ始めました。
自分のやりたいことや自分に適した研究スタイルを模索した末に、学部で学んだ専攻の経験を生かしつつ大学院で新しい分野に進んでみようと思い切り、今の研究室と出会うことができました。
思い返せば、「自分は何をテーマにどのような手法で研究したいのか」という気持ちを大切に進路を考えたことが、思う存分研究できている今の自分につながっているなと感じます。
まずは、自分の気持ちに素直に向き合ってみることが大切だと思います。
また、行き詰まったときは周りの先生に相談したり、外部の研究機関が開催するイベントなどに足を運んでみるのも、良い刺激を得られるのでおすすめです。
本記事の内容が高校生や大学学部生の皆さんにとって、何年後かに大学院進学を考えるときの一助になればとても嬉しいです。
皆さんと一緒に研究できる日を楽しみに待っています。
最後までお読みいただき、ありがとうございました。
参考文献
本記事で説明してきた「エピジェネティクス 」と「コンピュータによる解析手法」に関連した、書籍・Webサイト・論文を紹介します。
参考書籍・Webサイト
- THE CELL 細胞の分子生物学 第6版(ニュートンプレス)ARBERTS他 監訳:中村桂子・松原謙一 翻訳:青山聖子他
こちらは、大学学部生レベルを対象に分子生物学の基礎を解説した入門書です。
細胞の構造、遺伝子発現、細胞分化など章ごとにテーマが分かれていて、イラスト付きで初学者にも親しみやすい構成になっています。
「第7章 遺伝子発現の調節」では、エピジェネティクスの基礎部分が解説されています。
- エピジェネティクスとは?(国立がん研究センター研究所Webサイト)
上記のWebサイトでも、エピジェネティクスについて模式図を使った簡単な解説が載っています。
私たちが研究手法として用いている、コンピュータによる遺伝情報データ解析の一連の流れを動画で詳しく学ぶことができます。
データ解析の流れはひとつではなく研究目的によっても様々なので、これらの動画で紹介している手順やソフトウェアは解析方法の一例だとお考えください。
参考研究論文
D.C. Lagace, M.W. Nachtigal, Inhibition of histone deacetylase activity by valproic acid blocks adipogenesis. J. Biol. Chem. 2004, 279(18):18851– 18860.
EJ. Yoo et al., Down-regulation of histone deacetylases stimulates adipocyte differentiation. J. Biol. Chem. 2006, 281(10):6608–6615.
Nicolas D et al., Modulation of transcriptional burst frequency by histone acetylation. Proc. Natl. Acad. Sci. USA. 2018, 115(27):7153–7158.
A. Shah, A. Oldenburg, and P. Collas. A hyper-dynamic nature of bivalent promoter states underlies coordinated developmental gene expression modules. BMC Genomics. 2014, 15(1):1–13.
Wu H et al., Chromatin dynamics regulate mesenchymal stem cell lineage specification and differentiation to osteogenesis. Biochim Biophys Acta. 2017, 1860(4):438-449